London-based analytics company Nimble Learn has announced a breakthrough in the accessibility of large and complex open data sets.
Open Data Blend is the collective name for a set of services that are designed to produce analysis-ready open data and reduce the time and cost of sifting through large open data sets.It’s primarily aimed at data engineers, data analysts and data scientists, with potential applications in areas as diverse as pharmaceuticals, road safety and car maintenance.
Open Data Blend is the result of over six years of research and development into open data publishing, data engineering and modern data warehousing, and more analysis-ready datasets are due to be added over time.
Michael Amadi, founder of Nimble Learn, said: “Our data engineering team have been hard at work building out a sustainable service that curates large open data from the UK, transforms it into analysis-ready datasets, enriches it with derived values, and makes it available through a frictionless open data catalogue.“
We have the fundamental belief that everyone should have access to refined and frictionless open data, and Open Data Blend is a significant step along that path.”
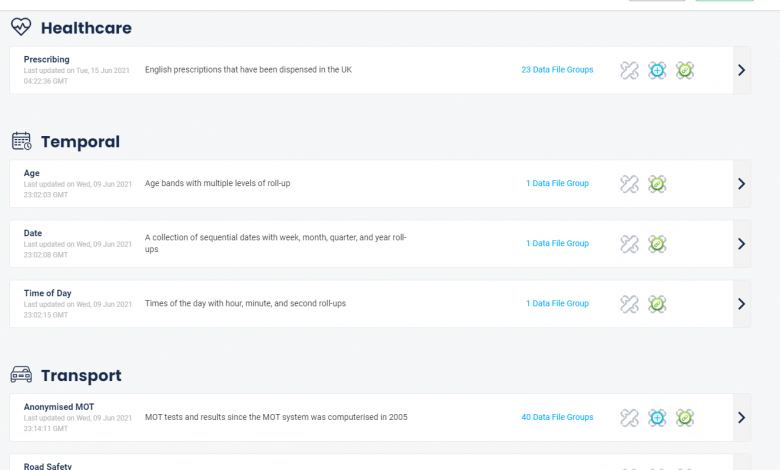
The openly-licensed data features a fast, lightweight data catalogue user interface, as well as an open access data catalogue and bulk data API that is built on open standards.Initial data sets include data relating to drugs prescribed by NHS England, MOT test results since the system was computerised in 2005, and road safety statistics in Great Britain.
Another service, Open Data Blend Analytics, enables data analysts and data scientists to analyse the datasets “at the speed of thought”, thereby allowing for much quicker insights and ultimately business value.“
Open Data Blend Analytics surfaces our datasets through a rich semantic data model that can be connected to and analysed from BI tools like Excel, Power BI and Tableau,” added Amadi.
Browse through the Open Data Blend Datasets, or find out more information about Open Data Blend Analytics.
Published on PRFIRE